-
1. Erste Schritte
-
2. Git Grundlagen
-
3. Git Branching
- 3.1 Branches auf einen Blick
- 3.2 Einfaches Branching und Merging
- 3.3 Branch-Management
- 3.4 Branching-Workflows
- 3.5 Remote-Branches
- 3.6 Rebasing
- 3.7 Zusammenfassung
-
4. Git auf dem Server
- 4.1 Die Protokolle
- 4.2 Git auf einem Server einrichten
- 4.3 Erstellung eines SSH-Public-Keys
- 4.4 Einrichten des Servers
- 4.5 Git-Daemon
- 4.6 Smart HTTP
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 Von Drittanbietern gehostete Optionen
- 4.10 Zusammenfassung
-
5. Verteiltes Git
-
6. GitHub
-
7. Git Tools
- 7.1 Revisions-Auswahl
- 7.2 Interaktives Stagen
- 7.3 Stashen und Bereinigen
- 7.4 Deine Arbeit signieren
- 7.5 Suchen
- 7.6 Den Verlauf umschreiben
- 7.7 Reset entzaubert
- 7.8 Fortgeschrittenes Merging
- 7.9 Rerere
- 7.10 Debuggen mit Git
- 7.11 Submodule
- 7.12 Bundling
- 7.13 Replace (Ersetzen)
- 7.14 Anmeldeinformationen speichern
- 7.15 Zusammenfassung
-
8. Git einrichten
- 8.1 Git Konfiguration
- 8.2 Git-Attribute
- 8.3 Git Hooks
- 8.4 Beispiel für Git-forcierte Regeln
- 8.5 Zusammenfassung
-
9. Git und andere VCS-Systeme
- 9.1 Git als Client
- 9.2 Migration zu Git
- 9.3 Zusammenfassung
-
10. Git Interna
-
A1. Anhang A: Git in anderen Umgebungen
- A1.1 Grafische Schnittstellen
- A1.2 Git in Visual Studio
- A1.3 Git in Visual Studio Code
- A1.4 Git in IntelliJ / PyCharm / WebStorm / PhpStorm / RubyMine
- A1.5 Git in Sublime Text
- A1.6 Git in Bash
- A1.7 Git in Zsh
- A1.8 Git in PowerShell
- A1.9 Zusammenfassung
-
A2. Anhang B: Git in Ihre Anwendungen einbetten
- A2.1 Die Git-Kommandozeile
- A2.2 Libgit2
- A2.3 JGit
- A2.4 go-git
- A2.5 Dulwich
-
A3. Anhang C: Git Kommandos
- A3.1 Setup und Konfiguration
- A3.2 Projekte importieren und erstellen
- A3.3 Einfache Snapshot-Funktionen
- A3.4 Branching und Merging
- A3.5 Projekte gemeinsam nutzen und aktualisieren
- A3.6 Kontrollieren und Vergleichen
- A3.7 Debugging
- A3.8 Patchen bzw. Fehlerkorrektur
- A3.9 E-mails
- A3.10 Externe Systeme
- A3.11 Administration
- A3.12 Basisbefehle
10.2 Git Interna - Git Objekte
Git Objekte
Git ist ein inhalts-adressierbares Dateisystem. Toll. Und was bedeutet das? Dies bedeutet, dass der Kern von Git ein einfacher Schlüssel-Wert-Datenspeicher ist. Dies bedeutet, dass du jede Art von Inhalt in ein Git-Repository einfügen kannst. Git gibt dir einen eindeutigen Schlüssel zurück, mit dem du den Inhalt später abrufen kannst.
Schauen wir uns als Beispiel den Installationsbefehl git hash-object an, der einige Daten aufnimmt, sie in deinem .git/objects Verzeichnis (der object database) speichert und dir den eindeutigen Schlüssel zurückgibt, der nun auf dieses Datenobjekt verweist.
Zunächst initialisierst du ein neues Git-Repository und stellst sicher, dass sich (wie erwartet) nichts im objects Verzeichnis befindet:
$ git init test
Initialized empty Git repository in /tmp/test/.git/
$ cd test
$ find .git/objects
.git/objects
.git/objects/info
.git/objects/pack
$ find .git/objects -type fGit hat das Verzeichnis objects initialisiert und darin die Unterverzeichnisse pack und info erstellt, aber es gibt darin keine regulären Dateien.
Jetzt erstellen wir mit git hash-object ein neues Datenobjekt und speichern es manuell in deiner neuen Git-Datenbank:
$ echo 'test content' | git hash-object -w --stdin
d670460b4b4aece5915caf5c68d12f560a9fe3e4In seiner einfachsten Form würde git hash-object den Inhalt, den du ihm übergeben hast, nehmen und würde lediglich den eindeutigen Schlüssel zurückgeben, der zum Speichern in deiner Git-Datenbank verwendet werden soll.
Die Option -w weist dann den Befehl an, den Schlüssel nicht einfach zurückzugeben, sondern das Objekt in die Datenbank zu schreiben.
Schließlich weist die Option --stdin git hash-object an, den zu verarbeitenden Inhalt von stdin abzurufen. Andernfalls würde der Befehl ein Dateinamenargument am Ende des Befehls erwarten, das den zu verwendenden Inhalt enthält.
Die Ausgabe des obigen Befehls ist ein Prüfsummen-Hash mit 40 Zeichen. Dies ist der SHA-1-Hash – eine Prüfsumme des Inhalts, den du speicherst, sowie eine Kopfzeile, über die du in Kürze mehr erfahren wirst. Jetzt kannst du sehen, wie Git deine Daten gespeichert hat:
$ find .git/objects -type f
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4Wenn du dein Verzeichnis objects erneut untersuchst, kannst du feststellen, dass es jetzt eine Datei für diesen neuen Inhalt enthält.
Auf diese Weise speichert Git den Inhalt initial — als einzelne Datei pro Inhaltselement, benannt mit der SHA-1-Prüfsumme des Inhalts und seiner Kopfzeile.
Das Unterverzeichnis wird mit den ersten 2 Zeichen des SHA-1 benannt, und der Dateiname enthält die verbleibenden 38 Zeichen.
Sobald du Inhalt in deiner Objektdatenbank hast, kannst du diesen Inhalt mit dem Befehl git cat-file untersuchen.
Dieser Befehl ist eine Art Schweizer Taschenmesser für die Inspektion von Git-Objekten.
Wenn du -p an cat-file übergibst, wird der Befehl angewiesen, zuerst den Inhaltstyp zu ermitteln und ihn dann entsprechend anzuzeigen:
$ git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4
test contentJetzt kannst du Inhalte zu Git hinzufügen und wieder herausziehen. Du kannst dies auch mit Inhalten in Dateien tun. Du kannst beispielsweise eine einfache Versionskontrolle für eine Datei durchführen. Erstelle zunächst eine neue Datei und speichere deren Inhalt in deiner Datenbank:
$ echo 'version 1' > test.txt
$ git hash-object -w test.txt
83baae61804e65cc73a7201a7252750c76066a30Schreibe dann neuen Inhalt in die Datei und speichere ihn erneut:
$ echo 'version 2' > test.txt
$ git hash-object -w test.txt
1f7a7a472abf3dd9643fd615f6da379c4acb3e3aDeine Objektdatenbank enthält nun beide Versionen dieser neuen Datei (sowie den ersten Inhalt, den du dort gespeichert hast):
$ find .git/objects -type f
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4Zu diesem Zeitpunkt kannst du deine lokale Kopie dieser test.txt Datei löschen und dann mit Git entweder die erste gespeicherte Version aus der Objektdatenbank abrufen:
$ git cat-file -p 83baae61804e65cc73a7201a7252750c76066a30 > test.txt
$ cat test.txt
version 1oder die zweite Version:
$ git cat-file -p 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a > test.txt
$ cat test.txt
version 2Es ist jedoch nicht sinnvoll, sich den SHA-1-Schlüssel für jede Version deiner Datei zu merken. Außerdem speicherst du den Dateinamen nicht in deinem System, sondern nur den Inhalt.
Dieser Objekttyp wird als blob bezeichnet.
Git kann dir den Objekttyp jedes Objekts in Git mitteilen, wenn du den SHA-1-Schlüssel mit git cat-file -t angibst:
$ git cat-file -t 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
blobBaum Objekte
Die nächste Art von Git-Objekte, die wir untersuchen, ist der baum, der das Problem des Speicherns des Dateinamens löst und es dir auch ermöglicht, eine Gruppe von Dateien zusammen zu speichern. Git speichert Inhalte auf ähnliche Weise wie ein UNIX-Dateisystem, jedoch etwas vereinfacht. Der gesamte Inhalt wird als Baum- und Blob-Objekte gespeichert, wobei Bäume UNIX-Verzeichniseinträgen entsprechen und Blobs mehr oder weniger Inodes oder Dateiinhalten entsprechen. Ein einzelnes Baumobjekt enthält einen oder mehrere Einträge, von denen jeder der SHA-1-Hash eines Blobs oder Teilbaums mit dem zugehörigen Modus, Typ und Dateinamen ist. Angenommen du hast ein Projekt, in dem der aktuellste Baum folgendermaßen aussieht:
$ git cat-file -p master^{tree}
100644 blob a906cb2a4a904a152e80877d4088654daad0c859 README
100644 blob 8f94139338f9404f26296befa88755fc2598c289 Rakefile
040000 tree 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0 libDie master^{tree} Syntax gibt das Baumobjekt an, auf das durch das letzte Commit in deinem master Branch verwiesen wird.
Beachte, dass das Unterverzeichnis lib kein Blob ist, sondern ein Zeiger auf einen anderen Baum:
$ git cat-file -p 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0
100644 blob 47c6340d6459e05787f644c2447d2595f5d3a54b simplegit.rb|
Anmerkung
|
Je nachdem, welche Shell du verwendest, können bei der Verwendung der In CMD unter Windows wird das Zeichen Wenn du ZSH verwendest, wird das Zeichen |
Konzeptionell sehen die von Git gespeicherten Daten ungefähr so aus:
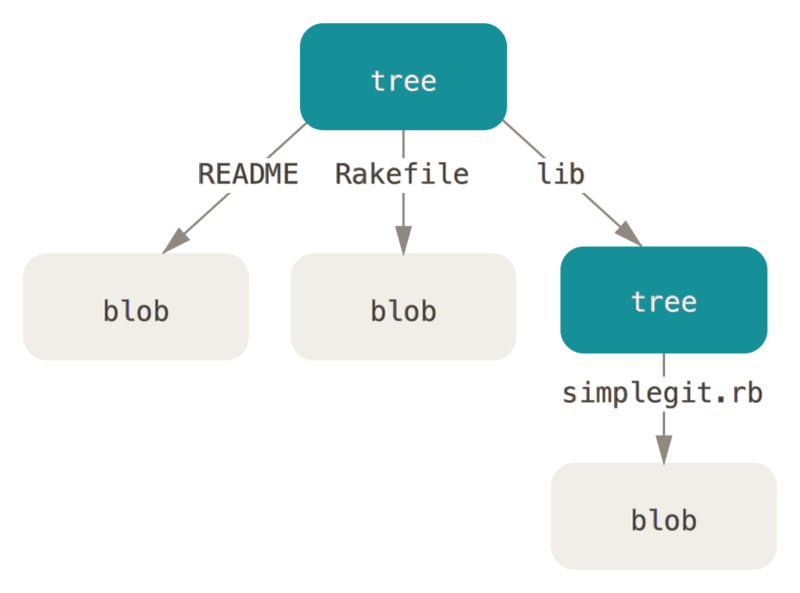
Du kannst ziemlich einfach deinen eigenen Baum erstellen.
Git erstellt normalerweise einen Baum, indem es den Status deines Staging-Bereichs oder Index übernimmt und eine Reihe von Baumobjekten daraus schreibt.
Um ein Baumobjekt zu erstellen, musst du zunächst einen Index einrichten, indem du einige Dateien bereitstellst.
Um einen Index mit einem einzigen Eintrag zu erstellen — der ersten Version Deiner test.txt Datei — kannst du den Basisbefehl git update-index verwenden.
Mit diesem Befehl fügst du die frühere Version der Datei test.txt künstlich einem neuen Staging-Bereich hinzu.
Du musst die Option --add übergeben, da die Datei in deinem Staging-Bereich noch nicht vorhanden ist (Du hast noch nicht einmal einen Staging-Bereich eingerichtet). --cacheinfo musst du angeben, weil die hinzugefügte Datei sich nicht in deinem Verzeichnis, sondern in deiner Datenbank befindet.
Dann gibst du den Modus, SHA-1 und Dateinamen an:
$ git update-index --add --cacheinfo 100644 \
83baae61804e65cc73a7201a7252750c76066a30 test.txtIn diesem Fall gibst du den Modus 100644 an, was bedeutet, dass es sich um eine normale Datei handelt.
Andere Optionen sind 100755, was bedeutet, dass es sich um eine ausführbare Datei handelt und 120000, was einen symbolischen Link angibt.
Der Modus stammt aus normalen UNIX-Modi, ist jedoch viel weniger flexibel — diese drei Modi sind die einzigen, die für Dateien (Blobs) in Git gültig sind (obwohl andere Modi für Verzeichnisse und Submodule verwendet werden).
Jetzt kannst du git write-tree verwenden, um den Staging-Bereich in ein Baumobjekt zu schreiben.
Es ist keine Option -w erforderlich. Durch Aufrufen dieses Befehls wird automatisch ein Baumobjekt aus dem Status des Index erstellt, wenn dieser Baum noch nicht vorhanden ist:
$ git write-tree
d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git cat-file -p d8329fc1cc938780ffdd9f94e0d364e0ea74f579
100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test.txtDu kannst auch überprüfen, ob es sich um ein Baumobjekt handelt, indem du denselben Befehl git cat-file verwendest, den du zuvor gesehen hast:
$ git cat-file -t d8329fc1cc938780ffdd9f94e0d364e0ea74f579
treeDu erstellst jetzt einen neuen Baum mit der zweiten Version von test.txt und einer neuen Datei:
$ echo 'new file' > new.txt
$ git update-index --cacheinfo 100644 \
1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
$ git update-index --add new.txtDein Staging-Bereich enthält jetzt die neue Version von test.txt sowie die neue Datei new.txt.
Schreibe diesen Baum aus (zeichne den Status des Staging-Bereichs oder des Index für ein Baumobjekt auf) und schau dir an, wie er aussieht:
$ git write-tree
0155eb4229851634a0f03eb265b69f5a2d56f341
$ git cat-file -p 0155eb4229851634a0f03eb265b69f5a2d56f341
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
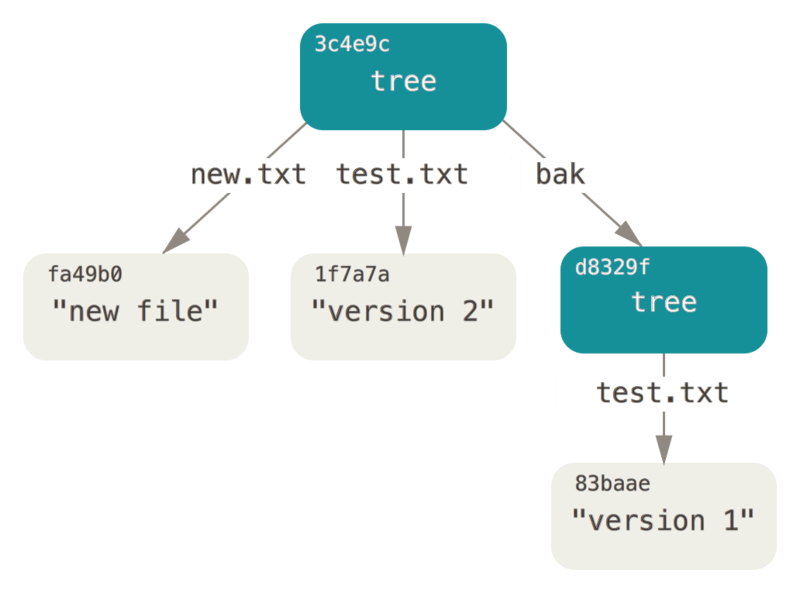
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txtBeachte, dass dieser Baum beide Dateieinträge enthält und dass der SHA-1 von test.txt der SHA-1 „Version 2“ von früher (1f7a7a) entspricht.
Zum rumprobieren füge diesem den ersten Baum als Unterverzeichnis hinzu.
Du kannst Bäume in deinem Staging-Bereich einlesen, indem du git read-tree aufrufst.
In diesem Fall kannst du einen vorhandenen Baum als Teilbaum in deinem Staging-Bereich einlesen, indem du die Option --prefix mit diesem Befehl verwendest:
$ git read-tree --prefix=bak d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git write-tree
3c4e9cd789d88d8d89c1073707c3585e41b0e614
$ git cat-file -p 3c4e9cd789d88d8d89c1073707c3585e41b0e614
040000 tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 bak
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txtWenn du aus dem soeben erstellten Baum ein Arbeitsverzeichnis erstellst, erhältst du die beiden Dateien in der obersten Ebene des Arbeitsverzeichnisses und ein Unterverzeichnis mit dem Namen bak, das die erste Version der Datei test.txt enthält.
Du kannst dir die Daten, die Git für diese Strukturen enthält, so vorstellen:
Commit Objekte
Wenn du alle oben genannten Schritte ausgeführt hast, verfügst du nun über drei Bäume, die die verschiedenen Schnappschüsse deines Projekts darstellen, die du verfolgen möchtest. Das bisherige Problem bleibt jedoch bestehen: Du müsst dir alle drei SHA-1-Werte merken, um die Schnappschüsse abzurufen. Du hast auch keine Informationen darüber, wer die Schnappschüsse gespeichert hat, wann sie gespeichert wurden oder warum sie gespeichert wurden. Dies sind die grundlegenden Informationen, die das Commit Objekt für dich speichert.
Um ein Commit Objekt zu erstellen, rufe commit-tree auf und gib einen einzelnen Baum SHA-1 an. Gib außerdem an welche Commit Objekte die direkten Vorgänger sind (falls überhaupt welche vorhanden sind).
Beginne mit dem ersten Baum, den du geschrieben hast:
$ echo 'First commit' | git commit-tree d8329f
fdf4fc3344e67ab068f836878b6c4951e3b15f3d|
Anmerkung
|
Du wirst vermutlich einen anderen Hash-Wert erhalten, da die Erstellungszeit und die Autorendaten unterschiedlich sind. Darüber hinaus kann zwar prinzipiell jedes Commit-Objekt genau reproduziert werden. Allerdings könnten aufgrund der technischen Details beim Erstellen dieses Buches die abgedruckten Commit-Hashes im Vergleich zu den entsprechenden Commits abweichen. Ersetze die Commit- und Tag-Hashes durch deine eigenen Prüfsummen in diesem Kapitel. |
Nun können du dir deine neues Commit-Objekt mit git cat-file ansehen:
$ git cat-file -p fdf4fc3
tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
author Scott Chacon <schacon@gmail.com> 1243040974 -0700
committer Scott Chacon <schacon@gmail.com> 1243040974 -0700
First commitDas Format für ein Commit Objekt ist einfach: Es gibt den Baum der obersten Ebene für den Snapshot des Projekts zu diesem Zeitpunkt an; Das übergeordnete Objekt, falls vorhanden, (das oben beschriebene Commit Objekt hat keine übergeordneten Objekte); die Autoren-/Committer-Informationen (genutzt werden deine Konfigurationseinstellungen user.name und user.email sowie einen Zeitstempel); eine leere Zeile und dann die Commit-Nachricht.
Als Nächstes schreibe die beiden anderen Commit Objekte, die jeweils auf das Commit verweisen, welches direkt davor erfolgte:
$ echo 'Second commit' | git commit-tree 0155eb -p fdf4fc3
cac0cab538b970a37ea1e769cbbde608743bc96d
$ echo 'Third commit' | git commit-tree 3c4e9c -p cac0cab
1a410efbd13591db07496601ebc7a059dd55cfe9Jedes der drei Commit-Objekte verweist auf einen der drei von dir erstellten Snapshot-Bäume.
Seltsamerweise hast du jetzt einen echten Git-Verlauf, den du mit dem Befehl git log anzeigen kannst, wenn du ihn beim letzten Commit SHA-1 ausführst:
$ git log --stat 1a410e
commit 1a410efbd13591db07496601ebc7a059dd55cfe9
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:15:24 2009 -0700
Third commit
bak/test.txt | 1 +
1 file changed, 1 insertion(+)
commit cac0cab538b970a37ea1e769cbbde608743bc96d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:14:29 2009 -0700
Second commit
new.txt | 1 +
test.txt | 2 +-
2 files changed, 2 insertions(+), 1 deletion(-)
commit fdf4fc3344e67ab068f836878b6c4951e3b15f3d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:09:34 2009 -0700
First commit
test.txt | 1 +
1 file changed, 1 insertion(+)Wundervoll.
Du hast gerade Basisbefehle der niedrigen Ebene ausgeführt, um einen Git-Verlauf zu erstellen, ohne einen der Standardbefehle zu verwenden.
Dies ist im Wesentlichen das, was Git tut, wenn du die Befehle git add und git commit ausführst — es speichert Blobs für die geänderten Dateien, aktualisiert den Index, schreibt Bäume und schreibt Commit-Objekte, die auf Bäume der oberste Ebene verweisen und die Commits, die unmittelbar vor ihnen aufgetreten sind.
Diese drei Haupt-Git-Objekte — der Blob, der Baum und das Commit – werden anfänglich als separate Dateien in deinem .git/objects Verzeichnis gespeichert.
Hier sind jetzt alle Objekte im Beispielverzeichnis, kommentiert mit dem, was sie speichern:
$ find .git/objects -type f
.git/objects/01/55eb4229851634a0f03eb265b69f5a2d56f341 # tree 2
.git/objects/1a/410efbd13591db07496601ebc7a059dd55cfe9 # commit 3
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a # test.txt v2
.git/objects/3c/4e9cd789d88d8d89c1073707c3585e41b0e614 # tree 3
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30 # test.txt v1
.git/objects/ca/c0cab538b970a37ea1e769cbbde608743bc96d # commit 2
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4 # 'test content'
.git/objects/d8/329fc1cc938780ffdd9f94e0d364e0ea74f579 # tree 1
.git/objects/fa/49b077972391ad58037050f2a75f74e3671e92 # new.txt
.git/objects/fd/f4fc3344e67ab068f836878b6c4951e3b15f3d # commit 1Wenn du allen internen Zeigern folgst, erhältst du eine Objektgrafik in etwa wie folgt:
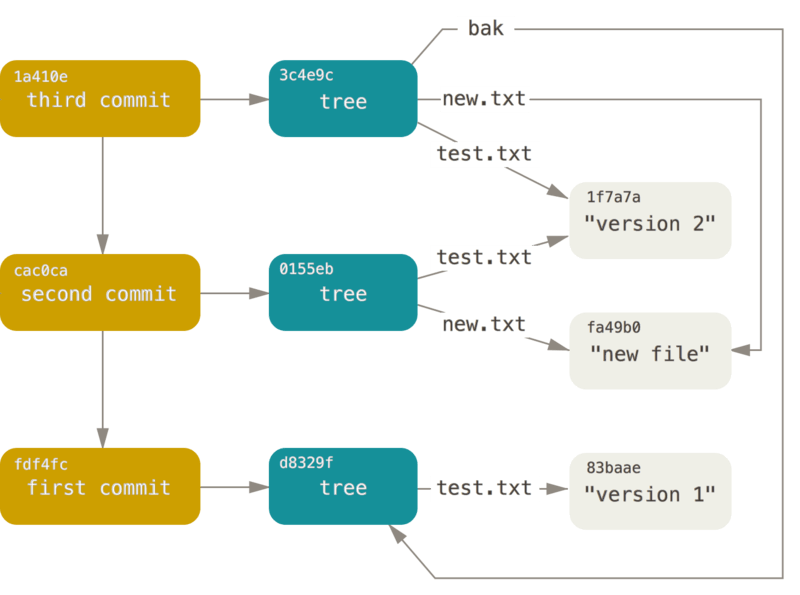
Objektspeicher
Wir haben bereits erwähnt, dass für jedes Objekt, das du in deine Git-Objektdatenbank übernimmst, ein Header gespeichert ist. Nehmen wir uns eine Minute Zeit, um zu sehen, wie Git seine Objekte speichert. Du wirst sehen, wie du ein Blob-Objekt — in diesem Fall die Zeichenfolge „what is up, doc?“ – interaktiv in der Ruby-Skriptsprache speicherst.
Du kannst den interaktiven Ruby-Modus mit dem Befehl irb starten:
$ irb
>> content = "what is up, doc?"
=> "what is up, doc?"Git erstellt zuerst einen Header, der mit der Identifizierung des Objekttyps beginnt — in diesem Fall ein Blob. Zu diesem ersten Teil des Headers fügt Git ein Leerzeichen hinzu, gefolgt von der Größe des Inhalts in Bytes, und fügt ein letztes Nullbyte hinzu:
>> header = "blob #{content.bytesize}\0"
=> "blob 16\u0000"Git verkettet den Header und den ursprünglichen Inhalt und berechnet dann die SHA-1-Prüfsumme dieses neuen Inhalts.
Du kannst den SHA-1-Wert einer Zeichenfolge in Ruby berechnen, indem du die SHA1-Digest-Bibliothek mit dem Befehl require hinzufügst und dann Digest::SHA1.hexdigest() mit der Zeichenfolge aufrufst:
>> store = header + content
=> "blob 16\u0000what is up, doc?"
>> require 'digest/sha1'
=> true
>> sha1 = Digest::SHA1.hexdigest(store)
=> "bd9dbf5aae1a3862dd1526723246b20206e5fc37"Vergleichen wir dies mit der Ausgabe von git hash-object.
Hier verwenden wir echo -n, um zu verhindern, dass der Eingabe eine neue Zeile hinzugefügt wird.
$ echo -n "what is up, doc?" | git hash-object --stdin
bd9dbf5aae1a3862dd1526723246b20206e5fc37Git komprimiert den neuen Inhalt mit zlib, was du in Ruby mit der zlib-Bibliothek tun kannst.
Zuerst musst du die Bibliothek hinzufügen und dann Zlib::Deflate.deflate() auf den Inhalt ausführen:
>> require 'zlib'
=> true
>> zlib_content = Zlib::Deflate.deflate(store)
=> "x\x9CK\xCA\xC9OR04c(\xCFH,Q\xC8,V(-\xD0QH\xC9O\xB6\a\x00_\x1C\a\x9D"Schließlich schreibst du deinen zlib-entpackten Inhalt auf ein Objekt auf der Festplatte.
Du bestimmst den Pfad des Objekts, das du ausschreiben möchtest (die ersten beiden Zeichen des SHA-1-Werts sind der Name des Unterverzeichnisses und die letzten 38 Zeichen der Dateiname in diesem Verzeichnis).
In Ruby kannst du die Funktion FileUtils.mkdir_p() verwenden, um das Unterverzeichnis zu erstellen, falls es nicht vorhanden ist.
Öffne dann die Datei mit File.open() und schreibe den zuvor mit zlib komprimierten Inhalt mit einem write() -Aufruf auf das resultierende Dateihandle in die Datei:
>> path = '.git/objects/' + sha1[0,2] + '/' + sha1[2,38]
=> ".git/objects/bd/9dbf5aae1a3862dd1526723246b20206e5fc37"
>> require 'fileutils'
=> true
>> FileUtils.mkdir_p(File.dirname(path))
=> ".git/objects/bd"
>> File.open(path, 'w') { |f| f.write zlib_content }
=> 32Lass uns den Inhalt des Objekts mit git cat-file überprüfen:
---
$ git cat-file -p bd9dbf5aae1a3862dd1526723246b20206e5fc37
what is up, doc?
---Das war’s – Du hast ein gültiges Git-Blob-Objekt erstellt.
Alle Git-Objekte werden auf dieselbe Weise gespeichert, nur mit unterschiedlichen Typen. Anstelle des String-Blobs beginnt der Header mit commit oder tree. Auch wenn der Blob-Inhalt nahezu beliebig sein kann, sind Commit- und Tree-Inhalt sehr spezifisch formatiert.