-
1. Começando
- 1.1 Sobre Controle de Versão
- 1.2 Uma Breve História do Git
- 1.3 O Básico do Git
- 1.4 A Linha de Comando
- 1.5 Instalando o Git
- 1.6 Configuração Inicial do Git
- 1.7 Pedindo Ajuda
- 1.8 Sumário
-
2. Fundamentos de Git
-
3. Branches no Git
-
4. Git on the Server
- 4.1 The Protocols
- 4.2 Getting Git on a Server
- 4.3 Generating Your SSH Public Key
- 4.4 Setting Up the Server
- 4.5 Git Daemon
- 4.6 Smart HTTP
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 Third Party Hosted Options
- 4.10 Summary
-
5. Distributed Git
-
6. GitHub
- 6.1 Configurando uma conta
- 6.2 Contribuindo em um projeto
- 6.3 Maintaining a Project
- 6.4 Managing an organization
- 6.5 Scripting GitHub
- 6.6 Summary
-
7. Git Tools
- 7.1 Revision Selection
- 7.2 Interactive Staging
- 7.3 Stashing and Cleaning
- 7.4 Signing Your Work
- 7.5 Searching
- 7.6 Rewriting History
- 7.7 Reset Demystified
- 7.8 Advanced Merging
- 7.9 Rerere
- 7.10 Debugging with Git
- 7.11 Submodules
- 7.12 Bundling
- 7.13 Replace
- 7.14 Credential Storage
- 7.15 Summary
-
8. Customizing Git
- 8.1 Git Configuration
- 8.2 Git Attributes
- 8.3 Git Hooks
- 8.4 An Example Git-Enforced Policy
- 8.5 Summary
-
9. Git and Other Systems
- 9.1 Git as a Client
- 9.2 Migrating to Git
- 9.3 Summary
-
10. Funcionamento Interno do Git
- 10.1 Encanamento e Porcelana
- 10.2 Objetos do Git
- 10.3 Referências do Git
- 10.4 Packfiles
- 10.5 The Refspec
- 10.6 Transfer Protocols
- 10.7 Maintenance and Data Recovery
- 10.8 Variáveis de ambiente
- 10.9 Sumário
-
A1. Appendix A: Git em Outros Ambientes
- A1.1 Graphical Interfaces
- A1.2 Git in Visual Studio
- A1.3 Git in Eclipse
- A1.4 Git in Bash
- A1.5 Git in Zsh
- A1.6 Git in Powershell
- A1.7 Resumo
-
A2. Appendix B: Embedding Git in your Applications
- A2.1 Command-line Git
- A2.2 Libgit2
- A2.3 JGit
-
A3. Appendix C: Git Commands
- A3.1 Setup and Config
- A3.2 Getting and Creating Projects
- A3.3 Basic Snapshotting
- A3.4 Branching and Merging
- A3.5 Sharing and Updating Projects
- A3.6 Inspection and Comparison
- A3.7 Debugging
- A3.8 Patching
- A3.9 Email
- A3.10 External Systems
- A3.11 Administration
- A3.12 Plumbing Commands
1.3 Começando - O Básico do Git
O Básico do Git
Então, em poucas palavras, o que é o Git ? Esta é uma parte que é importante aprender, porque se você entender o que o Git é e os fundamentos de como ele funciona, em seguida, provavelmente usar efetivamente o Git será muito mais fácil para você. Enquanto você estiver aprendendo sobre o Git, tente esquecer das coisas que você pode saber sobre outros VCSs, como Subversion e Perforce; isso vai ajudá-lo a evitar a confusão sutil ao usar a ferramenta. O Git armazena e vê informações de forma muito diferente do que esses outros sistemas, mesmo que a interface do usuário seja bem semelhante, e entender essas diferenças o ajudará a não ficar confuso. (Perforce )
Imagens, Não Diferenças
A principal diferença entre o Git e qualquer outro VCS (Subversion e similares) é a maneira como o Git trata seus dados. Conceitualmente, a maioria dos outros sistemas armazenam informação como uma lista de mudanças nos arquivos. Estes sistemas (CVS, Subversion, Perforce, Bazaar, e assim por diante) tratam a informação como um conjunto de arquivos e as mudanças feitas em cada arquivo ao longo do tempo.
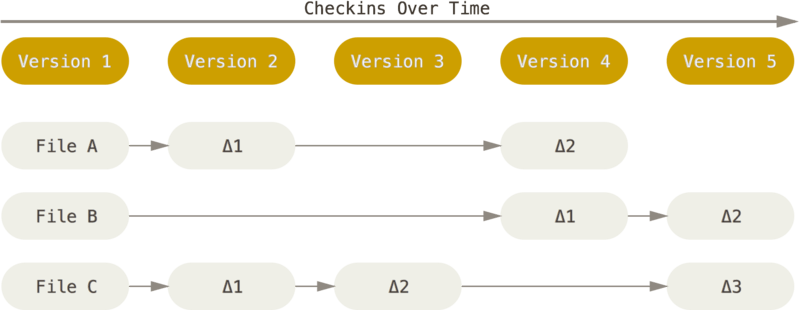
O Git não trata nem armazena seus dados desta forma. Em vez disso, o Git trata seus dados mais como um conjunto de imagens de um sistema de arquivos em miniatura. Toda vez que você fizer um commit, ou salvar o estado de seu projeto no Git, ele basicamente tira uma foto de todos os seus arquivos e armazena uma referência para esse conjunto de arquivos. Para ser eficiente, se os arquivos não foram alterados, o Git não armazena o arquivo novamente, apenas um link para o arquivo idêntico anterior já armazenado. O Git trata seus dados mais como um fluxo do estado dos arquivos.
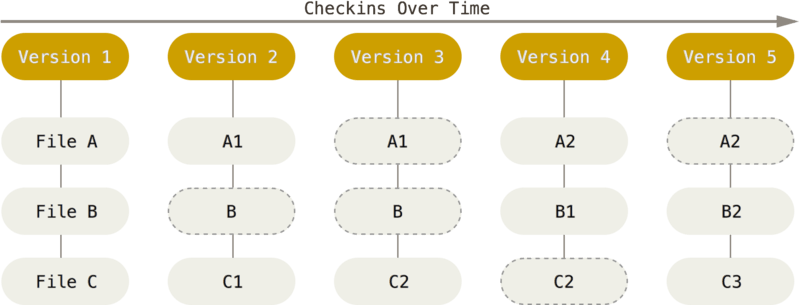
Esta é uma diferença importante entre o Git e quase todos os outros VCSs. Isto faz o Git reconsiderar quase todos os aspectos de controle de versão que a maioria dos outros sistemas copiaram da geração anterior. Isso faz com que o Git seja mais como um mini sistema de arquivos com algumas ferramentas incrivelmente poderosas, ao invés de simplesmente um VCS. Vamos explorar alguns dos benefícios que você ganha ao tratar seus dados desta forma quando cobrirmos ramificações no Git [ch03-git-branching].
Quase Todas as Operações são Locais
A maioria das operações no Git só precisa de arquivos e recursos locais para operar - geralmente nenhuma informação é necessária de outro computador da rede. Se você estiver acostumado com um CVCS onde a maioria das operações têm aquela demora causada pela latência da rede, este aspecto do Git vai fazer você pensar que os deuses da velocidade abençoaram o Git com poderes extraterrestres. Como você tem toda a história do projeto ali mesmo em seu disco local, a maioria das operações parecem quase instantâneas.
Por exemplo, para pesquisar o histórico do projeto, o Git não precisa sair para o servidor para obter a história e exibi-lo para você - ele simplesmente lê diretamente do seu banco de dados local. Isto significa que você vê o histórico do projeto quase que instantaneamente. Se você quiser ver as alterações introduzidas entre a versão atual de um arquivo e o arquivo de um mês atrás, o Git pode procurar o arquivo de um mês atrás e fazer um cálculo de diferença local, em vez de ter que quer pedir a um servidor remoto para fazê-lo ou puxar uma versão mais antiga do arquivo do servidor remoto para fazê-lo localmente.
Isto também significa que há muito pouco que você não pode fazer se você estiver desconectado ou sem VPN. Se você estiver em um avião ou um trem e quiser trabalhar um pouco, você pode fazer commits alegremente até conseguir conexão de rede e enviar os arquivos. Se você chegar em casa e não conseguir conectar ao VPN, você ainda poderá trabalhar. Em muitos outros sistemas, isso é impossível ou doloroso. No Perforce, por exemplo, você não pode fazer quase nada se você não estiver conectado ao servidor; e no Subversion e CVS, você pode editar os arquivos, mas não poderá enviar commits das alterações ao seu banco de dados (porque você não está conectado ao seu banco de dados). Isso pode não parecer muito, mas você poderá se surpreender com a grande diferença que isso pode fazer.
Git Tem Integridade
Tudo no Git passa por uma soma de verificações (checksum) antes de ser armazenado e é referenciado por esse checksum. Isto significa que é impossível mudar o conteúdo de qualquer arquivo ou pasta sem que Git saiba. Esta funcionalidade está incorporada no Git nos níveis mais baixos e é parte integrante de sua filosofia. Você não perderá informação durante a transferência e não receberá um arquivo corrompido sem que o Git seja capaz de detectar.
O mecanismo que o Git utiliza para esta soma de verificação é chamado um hash SHA-1. Esta é uma sequência de 40 caracteres composta de caracteres hexadecimais (0-9 e-f) e é calculada com base no conteúdo de uma estrutura de arquivo ou diretório no Git. Um hash SHA-1 é algo como o seguinte:
24b9da6552252987aa493b52f8696cd6d3b00373Você vai ver esses valores de hash em todo o lugar no Git porque ele os usa com frequência. Na verdade, o Git armazena tudo em seu banco de dados não pelo nome do arquivo, mas pelo valor de hash do seu conteúdo.
O Git Geralmente Somente Adiciona Dados
Quando você faz algo no Git, quase sempre dados são adicionados no banco de dados do Git - e não removidos. É difícil fazer algo no sistema que não seja reversível ou fazê-lo apagar dados de forma alguma. Como em qualquer VCS, você pode perder alterações que ainda não tenham sido adicionadas em um commit; mas depois de fazer o commit no Git do estado atual das alterações, é muito difícil que haja alguma perda, especialmente se você enviar regularmente o seu banco de dados para outro repositório.
Isso faz com que o uso do Git seja somente alegria, porque sabemos que podemos experimentar sem o perigo de estragar algo. Para um olhar mais aprofundado de como o Git armazena seus dados e como você pode recuperar dados que parecem perdidos, consulte Desfazendo coisas.
Os Três Estados
Agora, preste atenção. Esta é a principal coisa a lembrar sobre Git se você quiser que o resto do seu processo de aprendizagem ocorra sem problemas. O Git tem três estados principais que seus arquivos podem estar: committed, modificado (modified) e preparado (staged). Committed significa que os dados estão armazenados de forma segura em seu banco de dados local. Modificado significa que você alterou o arquivo, mas ainda não fez o commit no seu banco de dados. Preparado significa que você marcou a versão atual de um arquivo modificado para fazer parte de seu próximo commit.
Isso nos leva a três seções principais de um projeto Git: o diretório Git, o diretório de trabalho e área de preparo.
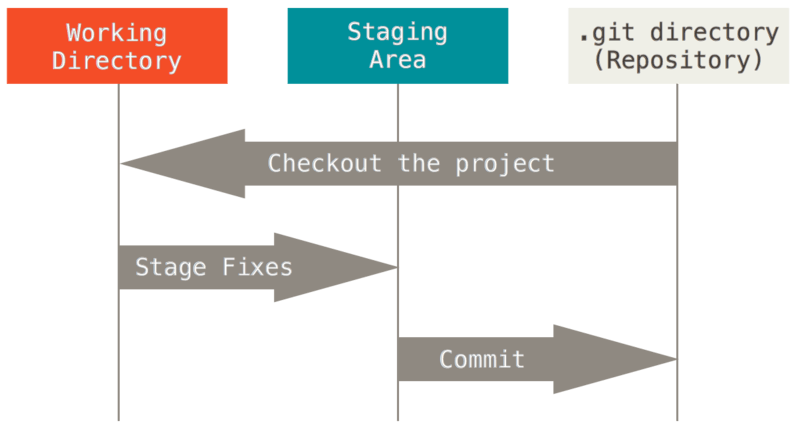
O diretório Git é onde o Git armazena os metadados e o banco de dados de objetos de seu projeto. Esta é a parte mais importante do Git, e é o que é copiado quando você clona um repositório de outro computador.
O diretório de trabalho é uma simples cópia de uma versão do projeto. Esses arquivos são pegos do banco de dados compactado no diretório Git e colocados no disco para você usar ou modificar.
A área de preparo é um arquivo, geralmente contido em seu diretório Git, que armazena informações sobre o que vai entrar em seu próximo commit. É por vezes referido como o “índice”, mas também é comum referir-se a ele como área de preparo (staging area).
O fluxo de trabalho básico Git é algo assim:
-
Você modifica arquivos no seu diretório de trabalho.
-
Você prepara os arquivos, adicionando imagens deles à sua área de preparo.
-
Você faz commit, o que leva os arquivos como eles estão na área de preparo e armazena essa imagens de forma permanente para o diretório do Git.
Se uma versão específica de um arquivo está no diretório Git, é considerado commited. Se for modificado, mas foi adicionado à área de preparo, é considerado preparado. E se ele for alterado depois de ter sido carregado, mas não foi preparado, ele é considerado modificado. Em [ch02-git-basics], você vai aprender mais sobre esses estados e como você pode tirar proveito deles ou pular a parte de preparação inteiramente.